6.1 Describing Variability
6.1: Describing Variability
6.1.1: Range
The range is a measure of the total spread of values in a quantitative dataset.
Learning Objective
Interpret the range as the overall dispersion of values in a dataset
Key Takeaways
Key Points
- Unlike other more popular measures of dispersion, the range actually measures total dispersion (between the smallest and largest values) rather than relative dispersion around a measure of central tendency.
- The range is measured in the same units as the variable of reference and, thus, has a direct interpretation as such.
- Because the information the range provides is rather limited, it is seldom used in statistical analyses.
- The mid-range of a set of statistical data values is the arithmetic mean of the maximum and minimum values in a data set.
Key Terms
- dispersion
- the degree of scatter of data
- range
- the length of the smallest interval which contains all the data in a sample; the difference between the largest and smallest observations in the sample
In statistics, the range is a measure of the total spread of values in a quantitative dataset. Unlike other more popular measures of dispersion, the range actually measures total dispersion (between the smallest and largest values) rather than relative dispersion around a measure of central tendency.
Interpreting the Range
The range is interpreted as the overall dispersion of values in a dataset or, more literally, as the difference between the largest and the smallest value in a dataset. The range is measured in the same units as the variable of reference and, thus, has a direct interpretation as such. This can be useful when comparing similar variables but of little use when comparing variables measured in different units. However, because the information the range provides is rather limited, it is seldom used in statistical analyses.
For example, if you read that the age range of two groups of students is 3 in one group and 7 in another, then you know that the second group is more spread out (there is a difference of seven years between the youngest and the oldest student) than the first (which only sports a difference of three years between the youngest and the oldest student).
Mid-Range
The mid-range of a set of statistical data values is the arithmetic mean of the maximum and minimum values in a data set, defined as:

The mid-range is the midpoint of the range; as such, it is a measure of central tendency. The mid-range is rarely used in practical statistical analysis, as it lacks efficiency as an estimator for most distributions of interest because it ignores all intermediate points. The mid-range also lacks robustness, as outliers change it significantly. Indeed, it is one of the least efficient and least robust statistics.
However, it finds some use in special cases:
- It is the maximally efficient estimator for the center of a uniform distribution
- Trimmed mid-ranges address robustness
- As an L-estimator, it is simple to understand and compute.
6.1.2: Variance
Variance is the sum of the probabilities that various outcomes will occur multiplied by the squared deviations from the average of the random variable.
Learning Objective
Calculate variance to describe a population
Key Takeaways
Key Points
- When determining the “spread” of the population, we want to know a measure of the possible distances between the data and the population mean.
- When trying to determine the risk associated with a given set of options, the variance is a very useful tool.
- When dealing with the complete population the (population) variance is a constant, a parameter which helps to describe the population.
- When dealing with a sample from the population the (sample) variance is actually a random variable, whose value differs from sample to sample.
Key Terms
- deviation
- For interval variables and ratio variables, a measure of difference between the observed value and the mean.
- spread
- A numerical difference.
When describing data, it is helpful (and in some cases necessary) to determine the spread of a distribution. In describing a complete population, the data represents all the elements of the population. When determining the spread of the population, we want to know a measure of the possible distances between the data and the population mean. These distances are known as deviations.
The variance of a data set measures the average square of these deviations. More specifically, the variance is the sum of the probabilities that various outcomes will occur multiplied by the squared deviations from the average of the random variable. When trying to determine the risk associated with a given set of options, the variance is a very useful tool.
Calculating the Variance
Calculating the variance begins with finding the mean. Once the mean is known, the variance is calculated by finding the average squared deviation of each number in the sample from the mean. For the numbers 1, 2, 3, 4, and 5, the mean is 3. The calculation for finding the mean is as follows:

Once the mean is known, the variance can be calculated. The variance for the above set of numbers is:




A clear distinction should be made between dealing with the population or with a sample from it. When dealing with the complete population the (population) variance is a constant, a parameter which helps to describe the population. When dealing with a sample from the population the (sample) variance is actually a random variable, whose value differs from sample to sample.

Population of Cheetahs
The population variance can be very helpful in analyzing data of various wildlife populations.
6.1.3: Standard Deviation: Definition and Calculation
Standard deviation is a measure of the average distance between the values of the data in the set and the mean.
Learning Objective
Contrast the usefulness of variance and standard deviation
Key Takeaways
Key Points
- A low standard deviation indicates that the data points tend to be very close to the mean; a high standard deviation indicates that the data points are spread out over a large range of values.
- In addition to expressing the variability of a population, standard deviation is commonly used to measure confidence in statistical conclusions.
- To calculate the population standard deviation, first compute the difference of each data point from the mean, and square the result of each. Next, compute the average of these values, and take the square root.
- The standard deviation is a “natural” measure of statistical dispersion if the center of the data is measured about the mean because the standard deviation from the mean is smaller than from any other point.
Key Terms
- normal distribution
- A family of continuous probability distributions such that the probability density function is the normal (or Gaussian) function.
- coefficient of variation
- The ratio of the standard deviation to the mean.
- mean squared error
- A measure of the average of the squares of the “errors”; the amount by which the value implied by the estimator differs from the quantity to be estimated.
- standard deviation
- a measure of how spread out data values are around the mean, defined as the square root of the varianc
Example
The average height for adult men in the United States is about 70 inches, with a standard deviation of around 3 inches. This means that most men (about 68%, assuming a normal distribution) have a height within 3 inches of the mean (67–73 inches) – one standard deviation – and almost all men (about 95%) have a height within 6 inches of the mean (64–76 inches) – two standard deviations. If the standard deviation were zero, then all men would be exactly 70 inches tall. If the standard deviation were 20 inches, then men would have much more variable heights, with a typical range of about 50–90 inches. Three standard deviations account for 99.7% of the sample population being studied, assuming the distribution is normal (bell-shaped).
Since the variance is a squared quantity, it cannot be directly compared to the data values or the mean value of a data set. It is therefore more useful to have a quantity that is the square root of the variance. The standard error is an estimate of how close to the population mean your sample mean is likely to be, whereas the standard deviation is the degree to which individuals within the sample differ from the sample mean. This quantity is known as the standard deviation.
Standard deviation (represented by the symbol sigma, ) shows how much variation or dispersion exists from the average (mean), or expected value. More precisely, it is a measure of the average distance between the values of the data in the set and the mean. A low standard deviation indicates that the data points tend to be very close to the mean; a high standard deviation indicates that the data points are spread out over a large range of values. A useful property of standard deviation is that, unlike variance, it is expressed in the same units as the data.
In statistics, the standard deviation is the most common measure of statistical dispersion. However, in addition to expressing the variability of a population, standard deviation is commonly used to measure confidence in statistical conclusions. For example, the margin of error in polling data is determined by calculating the expected standard deviation in the results if the same poll were to be conducted multiple times.
Basic Calculation
Consider a population consisting of the following eight values:
2, 4, 4, 4, 5, 5, 7, 9
These eight data points have a mean (average) of 5:

To calculate the population standard deviation, first compute the difference of each data point from the mean, and square the result of each:
Next, compute the average of these values, and take the square root:

This quantity is the population standard deviation, and is equal to the square root of the variance. The formula is valid only if the eight values we began with form the complete population. If the values instead were a random sample drawn from some larger parent population, then we would have divided by 7 (which is ) instead of 8 (which is ) in the denominator of the last formula, and then the quantity thus obtained would be called the sample standard deviation.
Estimation
The sample standard deviation, , is a statistic known as an estimator. In cases where the standard deviation of an entire population cannot be found, it is estimated by examining a random sample taken from the population and computing a statistic of the sample. Unlike the estimation of the population mean, for which the sample mean is a simple estimator with many desirable properties ( unbiased, efficient, maximum likelihood), there is no single estimator for the standard deviation with all these properties. Therefore, unbiased estimation of standard deviation is a very technically involved problem.
As mentioned above, most often the standard deviation is estimated using the corrected sample standard deviation (using ). However, other estimators are better in other respects:
- Using the uncorrected estimator (using ) yields lower mean squared error.
- Using (for the normal distribution) almost completely eliminates bias.
Relationship with the Mean
The mean and the standard deviation of a set of data are usually reported together. In a certain sense, the standard deviation is a “natural” measure of statistical dispersion if the center of the data is measured about the mean. This is because the standard deviation from the mean is smaller than from any other point. Variability can also be measured by the coefficient of variation, which is the ratio of the standard deviation to the mean.
Often, we want some information about the precision of the mean we obtained. We can obtain this by determining the standard deviation of the sample mean, which is the standard deviation divided by the square root of the total amount of numbers in a data set:


Standard Deviation Diagram
Dark blue is one standard deviation on either side of the mean. For the normal distribution, this accounts for 68.27 percent of the set; while two standard deviations from the mean (medium and dark blue) account for 95.45 percent; three standard deviations (light, medium, and dark blue) account for 99.73 percent; and four standard deviations account for 99.994 percent.
6.1.4: Interpreting the Standard Deviation
The practical value of understanding the standard deviation of a set of values is in appreciating how much variation there is from the mean.
Learning Objective
Derive standard deviation to measure the uncertainty in daily life examples
Key Takeaways
Key Points
- A large standard deviation indicates that the data points are far from the mean, and a small standard deviation indicates that they are clustered closely around the mean.
- When deciding whether measurements agree with a theoretical prediction, the standard deviation of those measurements is of crucial importance.
- In finance, standard deviation is often used as a measure of the risk associated with price-fluctuations of a given asset (stocks, bonds, property, etc. ), or the risk of a portfolio of assets.
Key Terms
- disparity
- the state of being unequal; difference
- standard deviation
- a measure of how spread out data values are around the mean, defined as the square root of the variance
Example
In finance, standard deviation is often used as a measure of the risk associated with price-fluctuations of a given asset (stocks, bonds, property, etc.), or the risk of a portfolio of assets. Risk is an important factor in determining how to efficiently manage a portfolio of investments because it determines the variation in returns on the asset and/or portfolio and gives investors a mathematical basis for investment decisions. When evaluating investments, investors should estimate both the expected return and the uncertainty of future returns. Standard deviation provides a quantified estimate of the uncertainty of future returns.
A large standard deviation, which is the square root of the variance, indicates that the data points are far from the mean, and a small standard deviation indicates that they are clustered closely around the mean. For example, each of the three populations , , and has a mean of 7. Their standard deviations are 7, 5, and 1, respectively. The third population has a much smaller standard deviation than the other two because its values are all close to 7.
Standard deviation may serve as a measure of uncertainty. In physical science, for example, the reported standard deviation of a group of repeated measurements gives the precision of those measurements. When deciding whether measurements agree with a theoretical prediction, the standard deviation of those measurements is of crucial importance. If the mean of the measurements is too far away from the prediction (with the distance measured in standard deviations), then the theory being tested probably needs to be revised. This makes sense since they fall outside the range of values that could reasonably be expected to occur, if the prediction were correct and the standard deviation appropriately quantified.
Application of the Standard Deviation
The practical value of understanding the standard deviation of a set of values is in appreciating how much variation there is from the average (mean).
Climate
As a simple example, consider the average daily maximum temperatures for two cities, one inland and one on the coast. It is helpful to understand that the range of daily maximum temperatures for cities near the coast is smaller than for cities inland. Thus, while these two cities may each have the same average maximum temperature, the standard deviation of the daily maximum temperature for the coastal city will be less than that of the inland city as, on any particular day, the actual maximum temperature is more likely to be farther from the average maximum temperature for the inland city than for the coastal one.
Sports
Another way of seeing it is to consider sports teams. In any set of categories, there will be teams that rate highly at some things and poorly at others. Chances are, the teams that lead in the standings will not show such disparity but will perform well in most categories. The lower the standard deviation of their ratings in each category, the more balanced and consistent they will tend to be. Teams with a higher standard deviation, however, will be more unpredictable.

Comparison of Standard Deviations
Example of two samples with the same mean and different standard deviations. The red sample has a mean of 100 and a SD of 10; the blue sample has a mean of 100 and a SD of 50. Each sample has 1,000 values drawn at random from a Gaussian distribution with the specified parameters.
6.1.5: Using a Statistical Calculator
For advanced calculating and graphing, it is often very helpful for students and statisticians to have access to statistical calculators.
Learning Objective
Analyze the use of R statistical software and TI-83 graphing calculators
Key Takeaways
Key Points
- Two of the most common calculators in use are the TI-83 series and the R statistical software environment.
- The TI-83 includes many features, including function graphing, polar/parametric/sequence graphing modes, statistics, trigonometric, and algebraic functions, along with many useful applications.
- The R language is widely used among statisticians and data miners for developing statistical software and data analysis.
- R provides a wide variety of statistical and graphical techniques, including linear and nonlinear modeling, classical statistical tests, time-series analysis, classification, and clustering.
- Another strength of R is static graphics, which can produce publication-quality graphs, including mathematical symbols.
Key Terms
- TI-83
- A calculator manufactured by Texas Instruments that is one of the most popular graphing calculators for statistical purposes.
- R
- A free software programming language and a software environment for statistical computing and graphics.
For many advanced calculations and/or graphical representations, statistical calculators are often quite helpful for statisticians and students of statistics. Two of the most common calculators in use are the TI-83 series and the R statistical software environment.
TI-83
The TI-83 series of graphing calculators, shown in , is manufactured by Texas Instruments. Released in 1996, it was one of the most popular graphing calculators for students. In addition to the functions present on normal scientific calculators, the TI-83 includes many andvanced features, including function graphing, polar/parametric/sequence graphing modes, statistics, trigonometric, and algebraic functions, along with many useful applications.

TI-83
The TI-83 series of graphing calculators is one of the most popular calculators for statistics students.
The TI-83 has a handy statistics mode (accessed via the “STAT” button) that will perform such functions as manipulation of one-variable statistics, drawing of histograms and box plots, linear regression, and even distribution tests.
R
R is a free software programming language and a software environment for statistical computing and graphics. The R language is widely used among statisticians and data miners for developing statistical software and data analysis. Polls and surveys of data miners are showing R’s popularity has increased substantially in recent years.
R is an implementation of the S programming language, which was created by John Chambers while he was at Bell Labs. R was created by Ross Ihaka and Robert Gentleman at the University of Auckland, New Zealand, and is currently developed by the R Development Core Team, of which Chambers is a member. R is a GNU project, which means it’s source code is freely available under the GNU General Public License.
R provides a wide variety of statistical and graphical techniques, including linear and nonlinear modeling, classical statistical tests, time-series analysis, classification, and clustering. Another strength of R is static graphics, which can produce publication-quality graphs, including mathematical symbols. Dynamic and interactive graphics are available through additional packages.
R is easily extensible through functions and extensions, and the R community is noted for its active contributions in terms of packages. These packagers allow specialized statistical techniques, graphical devices, import/export capabilities, reporting tools, et cetera. Due to its S heritage, R has stronger object-oriented programming facilities than most statistical computing languages.
6.1.6: Degrees of Freedom
The number of degrees of freedom is the number of values in the final calculation of a statistic that are free to vary.
Learning Objective
Outline an example of “degrees of freedom”
Key Takeaways
Key Points
- The degree of freedom can be defined as the minimum number of independent coordinates which can specify the position of the system completely.
- A parameter is a characteristic of the variable under examination as a whole; it is part of describing the overall distribution of values.
- As more degrees of freedom are lost, fewer and fewer different situations are accounted for by a model since fewer and fewer pieces of information could, in principle, be different from what is actually observed.
- Degrees of freedom can be seen as linking sample size to explanatory power.
Key Terms
- residual
- The difference between the observed value and the estimated function value.
- vector
- in statistics, a set of real-valued random variables that may be correlated
The number of independent ways by which a dynamical system can move without violating any constraint imposed on it is known as “degree of freedom. ” The degree of freedom can be defined as the minimum number of independent coordinates that completely specify the position of the system.
Consider this example: To compute the variance, first sum the square deviations from the mean. The mean is a parameter, a characteristic of the variable under examination as a whole, and a part of describing the overall distribution of values. Knowing all the parameters, you can accurately describe the data. The more known (fixed) parameters you know, the fewer samples fit this model of the data. If you know only the mean, there will be many possible sets of data that are consistent with this model. However, if you know the mean and the standard deviation, fewer possible sets of data fit this model.
In computing the variance, first calculate the mean, then you can vary any of the scores in the data except one. This one score left unexamined can always be calculated accurately from the rest of the data and the mean itself.
As an example, take the ages of a class of students and find the mean. With a fixed mean, how many of the other scores (there are N of them remember) could still vary? The answer is N-1 independent pieces of information (degrees of freedom) that could vary while the mean is known. One piece of information cannot vary because its value is fully determined by the parameter (in this case the mean) and the other scores. Each parameter that is fixed during our computations constitutes the loss of a degree of freedom.
Imagine starting with a small number of data points and then fixing a relatively large number of parameters as we compute some statistic. We see that as more degrees of freedom are lost, fewer and fewer different situations are accounted for by our model since fewer and fewer pieces of information could, in principle, be different from what is actually observed.
Put informally, the “interest” in our data is determined by the degrees of freedom. If there is nothing that can vary once our parameter is fixed (because we have so very few data points, maybe just one) then there is nothing to investigate. Degrees of freedom can be seen as linking sample size to explanatory power.
The degrees of freedom are also commonly associated with the squared lengths (or “sum of squares” of the coordinates) of random vectors and the parameters of chi-squared and other distributions that arise in associated statistical testing problems.
Notation and Residuals
In equations, the typical symbol for degrees of freedom is (lowercase Greek letter nu). In text and tables, the abbreviation “d.f. ” is commonly used.
In fitting statistical models to data, the random vectors of residuals are constrained to lie in a space of smaller dimension than the number of components in the vector. That smaller dimension is the number of degrees of freedom for error. In statistical terms, a random vector is a list of mathematical variables each of whose value is unknown, either because the value has not yet occurred or because there is imperfect knowledge of its value. The individual variables in a random vector are grouped together because there may be correlations among them. Often they represent different properties of an individual statistical unit (e.g., a particular person, event, etc.).
A residual is an observable estimate of the unobservable statistical error. Consider an example with men’s heights and suppose we have a random sample of n people. The sample mean could serve as a good estimator of the population mean. The difference between the height of each man in the sample and the observable sample mean is a residual. Note that the sum of the residuals within a random sample is necessarily zero, and thus the residuals are necessarily not independent.
Perhaps the simplest example is this. Suppose X1,…,Xn are random variables each with expected value μ, and let

be the “sample mean. ” Then the quantities

are residuals that may be considered estimates of the errors Xi − μ. The sum of the residuals is necessarily 0. If one knows the values of any n − 1 of the residuals, one can thus find the last one. That means they are constrained to lie in a space of dimension n − 1, and we say that “there are n − 1 degrees of freedom for error. ”
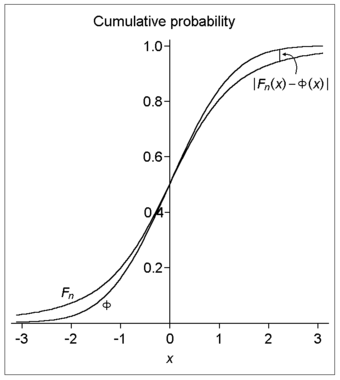
Degrees of Freedom
This image illustrates the difference (or distance) between the cumulative distribution functions of the standard normal distribution (Φ) and a hypothetical distribution of a standardized sample mean (Fn). Specifically, the plotted hypothetical distribution is a t distribution with 3 degrees of freedom.
6.1.7: Interquartile Range
The interquartile range (IQR) is a measure of statistical dispersion, or variability, based on dividing a data set into quartiles.
Learning Objectives
Calculate interquartile range based on a given data set
Key Takeaways
Key Points
- The interquartile range is equal to the difference between the upper and lower quartiles: IQR = Q3 − Q1.
- It is a trimmed estimator, defined as the 25% trimmed mid-range, and is the most significant basic robust measure of scale.
- The IQR is used to build box plots, which are simple graphical representations of a probability distribution.
Key Terms
- quartile
- any of the three points that divide an ordered distribution into four parts, each containing a quarter of the population
- outlier
- a value in a statistical sample which does not fit a pattern that describes most other data points; specifically, a value that lies 1.5 IQR beyond the upper or lower quartile
The interquartile range (IQR) is a measure of statistical dispersion, or variability, based on dividing a data set into quartiles. Quartiles divide an ordered data set into four equal parts. The values that divide these parts are known as the first quartile, second quartile and third quartile (Q1, Q2, Q3). The interquartile range is equal to the difference between the upper and lower quartiles:
IQR = Q3 − Q1
It is a trimmed estimator, defined as the 25% trimmed mid-range, and is the most significant basic robust measure of scale. As an example, consider the following numbers:
1, 13, 6, 21, 19, 2, 137
Put the data in numerical order: 1, 2, 6, 13, 19, 21, 137
Find the median of the data: 13
Divide the data into four quartiles by finding the median of all the numbers below the median of the full set, and then find the median of all the numbers above the median of the full set.
To find the lower quartile, take all of the numbers below the median: 1, 2, 6
Find the median of these numbers: take the first and last number in the subset and add their positions (not values) and divide by two. This will give you the position of your median:
1+3 = 4/2 = 2
The median of the subset is the second position, which is two. Repeat with numbers above the median of the full set: 19, 21, 137. Median is 1+3 = 4/2 = 2nd position, which is 21. This median separates the third and fourth quartiles.
Subtract the lower quartile from the upper quartile: 21-2=19. This is the Interquartile range, or IQR.
If there is an even number of values, then the position of the median will be in between two numbers. In that case, take the average of the two numbers that the median is between. Example: 1, 3, 7, 12. Median is 1+4=5/2=2.5th position, so it is the average of the second and third positions, which is 3+7=10/2=5. This median separates the first and second quartiles.
Uses
Unlike (total) range, the interquartile range has a breakdown point of 25%. Thus, it is often preferred to the total range. In other words, since this process excludes outliers, the interquartile range is a more accurate representation of the “spread” of the data than range.
The IQR is used to build box plots, which are simple graphical representations of a probability distribution. A box plot separates the quartiles of the data. All outliers are displayed as regular points on the graph. The vertical line in the box indicates the location of the median of the data. The box starts at the lower quartile and ends at the upper quartile, so the difference, or length of the boxplot, is the IQR.
On this boxplot in , the IQR is about 300, because Q1 starts at about 300 and Q3 ends at 600, and 600 – 300 = 300.
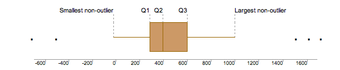
Interquartile Range
The IQR is used to build box plots, which are simple graphical representations of a probability distribution.
In a boxplot, if the median (Q2 vertical line) is in the center of the box, the distribution is symmetrical. If the median is to the left of the data (such as in the graph above), then the distribution is considered to be skewed right because there is more data on the right side of the median. Similarly, if the median is on the right side of the box, the distribution is skewed left because there is more data on the left side.
The range of this data is 1,700 (biggest outlier) – 500 (smallest outlier) = 2,200. If you wanted to leave out the outliers for a more accurate reading, you would subtract the values at the ends of both “whiskers:”
1,000 – 0 = 1,000
To calculate whether something is truly an outlier or not you use the formula 1.5 x IQR. Once you get that number, the range that includes numbers that are not outliers is [Q1 – 1.5(IQR), Q3 + 1.5(IQR)]. Anything lying outside those numbers are true outliers.
6.1.8: Measures of Variability of Qualitative and Ranked Data
Variability for qualitative data is measured in terms of how often observations differ from one another.
Learning Objective
Assess the use of IQV in measuring statistical dispersion in nominal distributions
Key Takeaways
Key Points
- The notion of “how far apart” does not make sense when evaluating qualitative data. Instead, we should focus on the unlikeability, or how often observations differ.
- An index of qualitative variation (IQV) is a measure of statistical dispersion in nominal distributions–or those dealing with qualitative data.
- The variation ratio is the simplest measure of qualitative variation. It is defined as the proportion of cases which are not the mode.
Key Terms
- qualitative data
- data centered around descriptions or distinctions based on some quality or characteristic rather than on some quantity or measured value
- variation ratio
- the proportion of cases not in the mode
The study of statistics generally places considerable focus upon the distribution and measure of variability of quantitative variables. A discussion of the variability of qualitative–or categorical– data can sometimes be absent. In such a discussion, we would consider the variability of qualitative data in terms of unlikeability. Unlikeability can be defined as the frequency with which observations differ from one another. Consider this in contrast to the variability of quantitative data, which ican be defined as the extent to which the values differ from the mean. In other words, the notion of “how far apart” does not make sense when evaluating qualitative data. Instead, we should focus on the unlikeability.
In qualitative research, two responses differ if they are in different categories and are the same if they are in the same category. Consider two polls with the simple parameters of “agree” or “disagree. ” These polls question 100 respondents. The first poll results in 75 “agrees” while the second poll only results in 50 “agrees. ” The first poll has less variability since more respondents answered similarly.
Index of Qualitative Variation
An index of qualitative variation (IQV) is a measure of statistical dispersion in nominal distributions–or those dealing with qualitative data. The following standardization properties are required to be satisfied:
- Variation varies between 0 and 1.
- Variation is 0 if and only if all cases belong to a single category.
- Variation is 1 if and only if cases are evenly divided across all categories.
In particular, the value of these standardized indices does not depend on the number of categories or number of samples. For any index, the closer to uniform the distribution, the larger the variance, and the larger the differences in frequencies across categories, the smaller the variance.
Variation Ratio
The variation ratio is a simple measure of statistical dispersion in nominal distributions. It is the simplest measure of qualitative variation. It is defined as the proportion of cases which are not the mode:

Just as with the range or standard deviation, the larger the variation ratio, the more differentiated or dispersed the data are; and the smaller the variation ratio, the more concentrated and similar the data are.
For example, a group which is 55% female and 45% male has a proportion of 0.55 females and, therefore, a variation ratio of:
This group is more dispersed in terms of gender than a group which is 95% female and has a variation ratio of only 0.05. Similarly, a group which is 25% Catholic (where Catholic is the modal religious preference) has a variation ratio of 0.75. This group is much more dispersed, religiously, than a group which is 85% Catholic and has a variation ratio of only 0.15.
6.1.9: Distorting the Truth with Descriptive Statistics
Descriptive statistics can be manipulated in many ways that can be misleading, including the changing of scale and statistical bias.
Learning Objectives
Key Takeaways
Key Points
- Descriptive statistics is a powerful form of research because it collects and summarizes vast amounts of data and information in a manageable and organized manner.
- Descriptive statistics, however, lacks the ability to identify the cause behind the phenomenon, correlate (associate) data, account for randomness, or provide statistical calculations that can lead to hypothesis or theories of populations studied.
- A statistic is biased if it is calculated in such a way that is systematically different from the population parameter of interest.
- Every time you try to describe a large set of observations with a single descriptive statistics indicator, you run the risk of distorting the original data or losing important detail.
Key Terms
- null hypothesis
- A hypothesis set up to be refuted in order to support an alternative hypothesis; presumed true until statistical evidence in the form of a hypothesis test indicates otherwise.
- descriptive statistics
- A branch of mathematics dealing with summarization and description of collections of data sets, including the concepts of arithmetic mean, median, and mode.
- bias
- (Uncountable) Inclination towards something; predisposition, partiality, prejudice, preference, predilection.
Descriptive statistics can be manipulated in many ways that can be misleading. Graphs need to be carefully analyzed, and questions must always be asked about “the story behind the figures. ” Potential manipulations include:
- changing the scale to change the appearence of a graph
- omissions and biased selection of data
- focus on particular research questions
- selection of groups
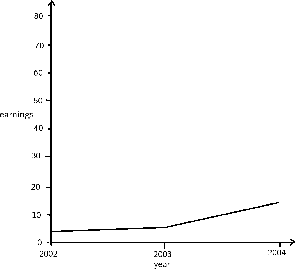
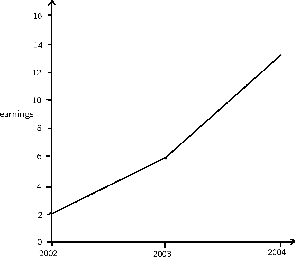
As an example of changing the scale of a graph, consider the following two figures, and .
Effects of Changing Scale
In this graph, the earnings scale is greater.
Effects of Changing Scale
This is a graph plotting yearly earnings.
Both graphs plot the years 2002, 2003, and 2004 along the x-axis. However, the y-axis of the first graph presents earnings from “0 to 10,” while the y-axis of the second graph presents earnings from “0 to 30. ” Therefore, there is a distortion between the two of the rate of increased earnings.
Statistical Bias
Bias is another common distortion in the field of descriptive statistics. A statistic is biased if it is calculated in such a way that is systematically different from the population parameter of interest. The following are examples of statistical bias.
- Selection bias occurs when individuals or groups are more likely to take part in a research project than others, resulting in biased samples.
- Spectrum bias arises from evaluating diagnostic tests on biased patient samples, leading to an overestimate of the sensitivity and specificity of the test.
- The bias of an estimator is the difference between an estimator’s expectations and the true value of the parameter being estimated.
- Omitted-variable bias appears in estimates of parameters in a regression analysis when the assumed specification is incorrect, in that it omits an independent variable that should be in the model.
- In statistical hypothesis testing, a test is said to be unbiased when the probability of rejecting the null hypothesis is less than or equal to the significance level when the null hypothesis is true, and the probability of rejecting the null hypothesis is greater than or equal to the significance level when the alternative hypothesis is true.
- Detection bias occurs when a phenomenon is more likely to be observed and/or reported for a particular set of study subjects.
- Funding bias may lead to selection of outcomes, test samples, or test procedures that favor a study’s financial sponsor.
- Reporting bias involves a skew in the availability of data, such that observations of a certain kind may be more likely to be reported and consequently used in research.
- Data-snooping bias comes from the misuse of data mining techniques.
- Analytical bias arises due to the way that the results are evaluated.
- Exclusion bias arises due to the systematic exclusion of certain individuals from the study
Limitations of Descriptive Statistics
Descriptive statistics is a powerful form of research because it collects and summarizes vast amounts of data and information in a manageable and organized manner. Moreover, it establishes the standard deviation and can lay the groundwork for more complex statistical analysis.
However, what descriptive statistics lacks is the ability to:
- identify the cause behind the phenomenon because it only describes and reports observations;
- correlate (associate) data or create any type of statistical relationship modeling relationship among variables;
- account for randomness; and
- provide statistical calculations that can lead to hypothesis or theories of populations studied.
To illustrate you can use descriptive statistics to calculate a raw GPA score, but a raw GPA does not reflect:
- how difficult the courses were, or
- the identity of major fields and disciplines in which courses were taken.
In other words, every time you try to describe a large set of observations with a single descriptive statistics indicator, you run the risk of distorting the original data or losing important detail.
6.1.10: Exploratory Data Analysis (EDA)
Exploratory data analysis is an approach to analyzing data sets in order to summarize their main characteristics, often with visual methods.
Learning Objectives
Key Takeaways
Key Points
- EDA is concerned with uncovering underlying structure, extracting important variables, detecting outliers and anomalies, testing underlying assumptions, and developing models.
- Exploratory data analysis was promoted by John Tukey to encourage statisticians to explore the data and possibly formulate hypotheses that could lead to new data collection and experiments.
- Robust statistics and nonparametric statistics both try to reduce the sensitivity of statistical inferences to errors in formulating statistical models.
- Many EDA techniques have been adopted into data mining and are being taught to young students as a way to introduce them to statistical thinking.
Key Terms
- skewed
- Biased or distorted (pertaining to statistics or information).
- data mining
- a technique for searching large-scale databases for patterns; used mainly to find previously unknown correlations between variables that may be commercially useful
- exploratory data analysis
- an approach to analyzing data sets that is concerned with uncovering underlying structure, extracting important variables, detecting outliers and anomalies, testing underlying assumptions, and developing models
Exploratory data analysis (EDA) is an approach to analyzing data sets in order to summarize their main characteristics, often with visual methods. It is a statistical practice concerned with (among other things):
- uncovering underlying structure,
- extracting important variables,
- detecting outliers and anomalies,
- testing underlying assumptions, and
- developing models.
Primarily, EDA is for seeing what the data can tell us beyond the formal modeling or hypothesis testing task. EDA is different from initial data analysis (IDA), which focuses more narrowly on checking assumptions required for model fitting and hypothesis testing, handling missing values, and making transformations of variables as needed. EDA encompasses IDA.
Exploratory data analysis was promoted by John Tukey to encourage statisticians to explore the data and possibly formulate hypotheses that could lead to new data collection and experiments. Tukey’s EDA was related to two other developments in statistical theory: robust statistics and nonparametric statistics. Both of these try to reduce the sensitivity of statistical inferences to errors in formulating statistical models. Tukey promoted the use of the five number summary of numerical data:
- the two extremes (maximum and minimum),
- the median, and
- the quartiles.
His reasoning was that the median and quartiles, being functions of the empirical distribution, are defined for all distributions, unlike the mean and standard deviation. Moreover, the quartiles and median are more robust to skewed or heavy-tailed distributions than traditional summaries (the mean and standard deviation).
Exploratory data analysis, robust statistics, and nonparametric statistics facilitated statisticians’ work on scientific and engineering problems. Such problems included the fabrication of semiconductors and the understanding of communications networks. These statistical developments, all championed by Tukey, were designed to complement the analytic theory of testing statistical hypotheses.
Objectives of EDA
Tukey held that too much emphasis in statistics was placed on statistical hypothesis testing (confirmatory data analysis) and more emphasis needed to be placed on using data to suggest hypotheses to test. In particular, he held that confusing the two types of analyses and employing them on the same set of data can lead to systematic bias owing to the issues inherent in testing hypotheses suggested by the data.
Subsequently, the objectives of EDA are to:
- suggest hypotheses about the causes of observed phenomena,
- assess assumptions on which statistical inference will be based,
- support the selection of appropriate statistical tools and techniques, and
- provide a basis for further data collection through surveys or experiments.
Techniques of EDA
Although EDA is characterized more by the attitude taken than by particular techniques, there are a number of tools that are useful. Many EDA techniques have been adopted into data mining and are being taught to young students as a way to introduce them to statistical thinking. Typical graphical techniques used in EDA are:
- Box plots
- Histograms
- Multi-vari charts
- Run charts
- Pareto charts
- Scatter plots
- Stem-and-leaf plots
- Parallel coordinates
- Odds ratios
- Multidimensional scaling
- Targeted projection pursuits
- Principal component analyses
- Parallel coordinate plots
- Interactive versions of these plots
- Projection methods such as grand tour, guided tour and manual tour
These EDA techniques aim to position these plots so as to maximize our natural pattern-recognition abilities. A clear picture is worth a thousand words!

Scatter Plots
A scatter plot is one visual statistical technique developed from EDA.
Attributions
- Range
-
“Descriptive statistics.”
http://en.wikipedia.org/wiki/Descriptive_statistics.
Wikipedia
CC BY-SA 3.0. -
“20130216 – Range – WikiofScience.”
http://wikiofscience.wikidot.com/print:20130216-range.
Wikidot
CC BY-SA.
- Variance
-
“Error 404.”
http://www.abs.gov.au/websitedbs/a3121120.nsf/89a5f3d8684682b6ca256de4002c809b/8a79c9ade4ea90ccca25794900128238!OpenDocument.
Austrailian Bureau of Statistics
CC BY. -
“Statistics/Summary/Variance.”
http://en.wikibooks.org/wiki/Statistics/Summary/Variance.
Wikibooks
CC BY-SA 3.0. -
“CheetahsSerengetiNationalParkApr2011.”
http://en.wikipedia.org/wiki/File:CheetahsSerengetiNationalParkApr2011.jpg.
Wikipedia
CC BY-SA. -
“Statistics/Summary/Variance.”
http://en.wikibooks.org/wiki/Statistics/Summary/Variance.
Wikibooks
CC BY-SA 3.0.
- Standard Deviation: Definition and Calculation
-
“Error 404.”
http://www.abs.gov.au/websitedbs/a3121120.nsf/89a5f3d8684682b6ca256de4002c809b/8a79c9ade4ea90ccca25794900128238!OpenDocument.
Austrailian Bureau of Statistics
CC BY. -
“coefficient of variation.”
http://en.wikipedia.org/wiki/coefficient%20of%20variation.
Wikipedia
CC BY-SA 3.0. -
“Free High School Science Texts Project, Statistics: Standard Deviation and Variance. September 17, 2013.”
http://cnx.org/content/m38858/latest/.
OpenStax CNX
CC BY 3.0. -
“Standard deviation diagram.”
http://commons.wikimedia.org/wiki/File:Standard_deviation_diagram.svg.
Wikimedia
CC BY.
- Interpreting the Standard Deviation
-
“Comparison standard deviations.”
http://commons.wikimedia.org/wiki/File:Comparison_standard_deviations.svg.
Wikimedia
Public domain.
- Using a Statistical Calculator
- Degrees of Freedom
-
“Errors and residuals in statistics.”
http://en.wikipedia.org/wiki/Errors_and_residuals_in_statistics.
Wikipedia
CC BY-SA 3.0. -
“Degrees of freedom (statistics).”
http://en.wikipedia.org/wiki/Degrees_of_freedom_(statistics).
Wikipedia
CC BY-SA 3.0. -
“Degrees of freedom (statistics).”
http://en.wikipedia.org/wiki/Degrees_of_freedom_(statistics).
Wikipedia
CC BY-SA 3.0. -
“Statistics Ground Zero/Degrees of freedom.”
http://en.wikibooks.org/wiki/Statistics_Ground_Zero/Degrees_of_freedom.
Wikibooks
CC BY-SA 3.0. -
“BerryEsseenTheoremCDFGraphExample.”
http://commons.wikimedia.org/wiki/File:BerryEsseenTheoremCDFGraphExample.png.
Wikimedia
Public domain.
- Interquartile Range
-
“2. Range and Interquartile Range.”
http://killianhma0910.wikispaces.com/2.+Range+and+Interquartile+Range.
killianhma0910 Wikispace
CC BY-SA 3.0. -
“killianHMA0910 – 2.
Range and Interquartile Range.”
http://killianhma0910.wikispaces.com/2.+Range+and+Interquartile+Range.
Wikispaces
CC BY-SA.
- Measures of Variability of Qualitative and Ranked Data
-
“Qualitative variation.”
http://en.wikipedia.org/wiki/Qualitative_variation.
Wikipedia
CC BY-SA 3.0.
- Distorting the Truth with Descriptive Statistics
-
“descriptive statistics.”
http://en.wiktionary.org/wiki/descriptive_statistics.
Wiktionary
CC BY-SA 3.0. -
“Descriptive Statistics.”
http://medanth.wikispaces.com/Descriptive+Statistics.
medanth Wikispace
CC BY-SA 3.0. -
“Free High School Science Texts Project, Statistics: Misuse of Statistics. September 17, 2013.”
http://cnx.org/content/m38864/latest/.
OpenStax CNX
CC BY 3.0. -
“Free High School Science Texts Project, Statistics: Misuse of Statistics. April 29, 2013.”
http://cnx.org/content/m38864/latest/.
OpenStax CNX
CC BY 3.0. -
“Free High School Science Texts Project, Statistics: Misuse of Statistics. April 29, 2013.”
http://cnx.org/content/m38864/latest/.
OpenStax CNX
CC BY 3.0.
- Exploratory Data Analysis (EDA)
-
“exploratory data analysis.”
http://en.wikipedia.org/wiki/exploratory%20data%20analysis.
Wikipedia
CC BY-SA 3.0. -
“Exploratory data analysis.”
http://en.wikipedia.org/wiki/Exploratory_data_analysis.
Wikipedia
CC BY-SA 3.0. -
“Scatter diagram for quality characteristic XXX.”
http://en.wikipedia.org/wiki/File:Scatter_diagram_for_quality_characteristic_XXX.svg.
Wikipedia
CC BY-SA.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}