4 Data Management and Analytics in Business
Learning Objectives
- Explain the basics of data.
- Discuss data storage and retrieval.
- Understand database management systems.
- Describe data modeling and analysis.
- Demonstrate knowledge of data visualization and descriptive analytics.
Introduction
Data management and analysis refer to the process of collecting, organizing, storing, and analyzing data to derive meaningful insight to help support business decisions. In business information systems, data management and analysis are critical components that empower organizations to make informed decisions, monitor progress, and evaluate overall performance.
Data management involves several steps, including data collection, data cleansing, data integration, and data storage. The process of data analysis involves identifying relevant data, finding patterns, and deriving insights to help organizations make strategic decisions.
Business information systems provide powerful tools to help with data management and analysis. For example, data warehouses, data lakes, and databases make it possible to store large volumes of data in a central repository, making it easy to access and analyze. Data visualization tools, such as dashboards and reports, help to present complex data in a clear and concise manner, making it easier for business leaders to interpret.
Effective data management and analysis can have a significant impact on business performance. By analyzing customer data, businesses can identify trends and preferences, improve customer engagement, and increase revenue. By analyzing process data, they can identify bottlenecks and inefficiencies and make changes to improve operational efficiency.
So, data management and analysis are critical components of any business information system, enabling organizations to make data-driven decisions that support their strategic goals.
What is Data?
 Data is a vital element in modern day society. It is defined as a collection of raw facts, statistics, figures or any other quantitative or qualitative information that can be processed, analyzed or interpreted. Data can be used to derive insights, make informed decisions, and is the backbone of most businesses, organizations and government functions.
Data is a vital element in modern day society. It is defined as a collection of raw facts, statistics, figures or any other quantitative or qualitative information that can be processed, analyzed or interpreted. Data can be used to derive insights, make informed decisions, and is the backbone of most businesses, organizations and government functions.
Data is categorized into two main types: qualitative and quantitative data. Qualitative data refers to descriptive data that cannot be measured or counted. Examples include opinions, emotions or perceptions of individuals. It is often collected through observations, interviews or surveys. Quantitative data, on the other hand, encompasses measurable data that can be quantified or put into numbers, usually through structured surveys, experiments or observations. Examples of quantitative data include numerical measurements such as statistics, prices or temperature readings.
Another way to classify data is by the level of measurement. This is known as the data hierarchy. The four levels of measurement in the data hierarchy are nominal, ordinal, interval and ratio.
Nominal data is the simplest form of data and is defined as data that can be sorted into categories, but does not have any numerical order. Examples of nominal data include ethnicities, hair color, or gender. This type of data can only be summarized using percentages, frequencies or modes.
Ordinal data is next level up in the hierarchy, and is a type of data that can be ranked or ordered. However, the difference between each rank is not always equal. Examples of ordinal data include responses from a Likert scale, which uses responses such as “strongly agree,” “agree,” “neutral,” “disagree,” and “strongly disagree”.
Interval data is another level up in the hierarchy and is defined as data that can be ranked and have equal intervals between values. This data has a set of fixed and meaningful differences between values. Examples include temperature, timelines and dates.
Ratio data is the highest level in the hierarchy and it is defined as data that has a meaningful zero point. This type of data allows for ratio comparisons and is the most mathematically precise category of data. Examples of ratio data include height, weight, and time.
Data-Driven Performance
It is important to mention that the type of data collected should determine the best data analysis approach. For instance, statistical analysis techniques such as regression analysis or time series analysis are most suited for processing quantitative data since it uses numerical values. On the other hand, qualitative data requires analysis through content analysis, ethnography, and grounded theory.
Data can also be used to monitor and analyze performance in various fields. For example, in the healthcare industry, data can be utilized to track patient outcomes, identify areas for improvement in patient care and treatment, and predict potential health risks based on demographic and health history data.
In the business world, data can be used to measure revenue, sales, and marketing performance, as well as track inventory and supply chain management. This can help businesses make informed decisions about resource allocation, product development, and marketing strategies.
Data can also be used to inform public policy decision-making. Governments can use data to identify trends, track progress on initiatives, and evaluate the impact of policies and programs. Policymakers can then use this information to make evidence-based decisions that benefit their constituents.
Data is a powerful tool with endless potential uses. With the right tools and techniques, it can be used to drive innovation, improve efficiency, and inform decision-making in virtually any industry or sector.”
Data, Information, Knowledge and Wisdom
Data, information, knowledge, and wisdom are terms that are often used interchangeably, but they have distinct meanings and differences.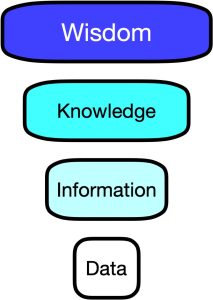
Data refers to raw, unorganized facts, figures, and statistics that are collected and stored. It can exist in various forms like text, numbers, images, audio, or video. For example, a list of names and their addresses is data. It provides no context or meaning and needs to be organized and processed to become useful.
Information is derived from data. It is data that has been analyzed, processed, or structured into a meaningful context. Information adds meaning and significance to data and provides answers to questions like who, what, when, where, and how. For instance, if the list of names and addresses were sorted by city, it would become information as it would give an indication of where each person lives.
Knowledge is the insights and understanding that is gained from information. Knowledge is the result of the application of the information to a particular context or situation. It involves both cognitive and experiential learning and requires the ability to interpret, evaluate, and apply information to solve problems, make decisions, or innovate. For example, if a marketer used the addresses to understand the customer demographic’s preferences and spending habits, it would result in knowledge.
Wisdom is the highest level of understanding and judgment that goes beyond knowledge. Wisdom is gained through experience, reflection, and intuition developed over years of learning and adapting. It is the ability to apply knowledge and make sound judgments that lead to positive outcomes. For instance, if the marketer used the knowledge gained to make changes in products and services that meet customers’ needs and preferences, it would demonstrate wisdom.
In conclusion, while data, information, knowledge, and wisdom are related, they have different meanings and implications. Understanding the differences can help individuals and organizations make informed decisions, innovate, and achieve their goals. Effective database management is essential in ensuring that data is transformed into useful information for knowledge and wisdom development.
Information Systems Contributions
Information systems are critical tools that can assist in managing data, information, knowledge, and wisdom. Here are some ways that information systems can support these efforts:
Data Management: Information systems can help manage data by providing automated data collection tools that capture data in real-time from different sources. These systems can also store and organize data in a structured format, making it easier to retrieve and analyze later. Information systems can also provide backup and recovery mechanisms to ensure the security and integrity of the data.
Information Management: Information systems can assist in the management of information by providing tools to analyze and interpret data, such as business intelligence and data analytics tools. These tools can help organizations understand patterns and trends in their data, identify opportunities for improvement, and make data-driven decisions. Information systems can also automate the process of sharing information across the organization, ensuring that everyone has access to the most up-to-date information.
Knowledge Management: Information systems can assist in the management of knowledge by providing tools to capture, store, and share knowledge within an organization. These tools can include knowledge management systems, document management systems, and collaboration platforms. These systems can help ensure that knowledge is accessible to everyone within the organization, regardless of their location or role. They can also provide mechanisms for knowledge sharing and collaboration, promoting innovation and continuous learning.
Wisdom Management.: Information systems can assist in the management of wisdom by providing tools to help individuals and organizations make informed decisions. These tools can include decision support systems, scenario planning tools, and predictive analytics. These systems can help individuals and organizations anticipate future outcomes, make informed decisions, and take proactive measures to achieve their goals.
In conclusion, information systems are critical tools in managing data, information, knowledge, and wisdom. By providing automated tools for data collection, storage, and analysis, information systems can help organizations make informed decisions and achieve their goals. By providing mechanisms for knowledge sharing and collaboration, information systems can promote innovation and continuous learning. And by providing tools for decision-making, information systems can assist individuals and organizations in achieving wisdom.
Data Storage and Retrieval
Data storage and retrieval are essential components of modern-day technology. As more and more data is generated, there is an increasing need to store it securely and efficiently. Additionally, it is equally important to be able to access and retrieve it promptly when needed. This is where databases, data warehouses, and data lakes come into play.
Databases
A database is a collection of data that is organized in a specific way to allow for efficient and easy retrieval. It is typically managed by a database management system (DBMS), which is a software system that allows users to interact with the database, perform operations such as adding, deleting, or modifying data, and extract information from it. The DBMS also ensures the security and integrity of the data by managing access permissions and maintaining consistency.
Databases can be further classified into relational and non-relational databases:
Relational Databases: In a relational database, data is stored in tables, with each table representing a specific entity or set of related entities. Each table is made up of columns that define the attributes of the entity or entities it represents, and rows that contain the actual data values. The data in the tables is related to each other through the use of keys, which are used to link data between the tables. The relational model is widely used, and databases such as Oracle, MySQL, and Microsoft SQL Server are popular examples of relational databases.
Non-Relational Databases: A non-relational database, flat-file database, or NoSQL database, is a database system that stores data in a non-tabular format, typically using document-oriented, key-value or graph data models. In contrast to relational databases, non-relational databases are more flexible and scalable as they do not require a rigid schema. Examples of NoSQL databases include MongoDB, Cassandra, and Redis.
Data Warehouses
Data warehouses are centralized repositories of integrated data, used for business intelligence and analytics. They collect data from various sources such as transactional databases, applications, and external sources, and organize them in a structured and easily accessible format.
Businesses use data warehouses for a variety of purposes, including:
Reporting and analysis: Data warehouses provide quick and easy access to data for reporting and analysis. Businesses can use the data to generate customized reports and gain insights into areas such as sales trends, customer behavior, and operational efficiency.
Decision-making: With timely and accurate data available in data warehouses, businesses can make informed decisions on a range of topics. This includes things like developing new products, expanding into new markets, and adjusting marketing strategies.
Consistency: Data warehouses ensure that data is consistent across all departments and functions within a business. This helps prevent errors or discrepancies and ensures that everyone is working from the same data.
Cost-effectiveness: By centralizing data in a data warehouse, businesses can save on costs associated with data storage, processing, and management. This is because data warehouses can handle large amounts of data, allowing businesses to consolidate their storage systems and reduce duplication of effort.
In short, data warehouses provide businesses with a powerful tool to manage their data and improve their decision-making capabilities.
Data Lakes
A data lake is a large, centralized repository that can store vast amounts of structured and unstructured data from multiple sources. It is a storage solution that allows businesses to store, process, and analyze large datasets without having to worry about the data’s structure or format. A data lake can store data from a variety of sources, including social media, customer interactions, machine logs, and operational systems.
In business, data lakes are used to store and analyze vast amounts of data, providing insights into customer behavior, market trends, and operational efficiency. With a data lake, businesses can have easy access to data from different sources, enabling them to make more informed decisions about product development, marketing, operations, and customer service.
Data lakes are also beneficial for machine learning and artificial intelligence applications, as they provide a large, diverse dataset for training models. In summary, data lakes can help businesses make sense of their data, derive valuable insights, and drive better business outcomes.
Using Databases
Databases are an essential tool in today’s information-driven world, allowing organizations to organize, store, and retrieve large amounts of data efficiently. A database is essentially a collection of related data that is stored in a structured format and accessed using a set of predefined queries or commands. These databases can be used to store and manage various types of information, from customer data and financial records to inventory and employee information.
Database Management Systems (DBMS)
A database management system (DBMS) is software that allows users to create, manipulate, and manage databases. A database is a collection of data that is organized, stored, and managed in a way that enables efficient access, retrieval, and modification of the data. DBMSs are used in various industries and settings, such as banking, healthcare, education, retail, and government, among others. Here are some examples of DBMSs and how they are used in a business setting:
Oracle Database: Oracle Database is a relational database management system that is widely used by large organizations to manage and store data. It provides various tools and functionalities for database management, including backup and recovery, access control, and data replication. In a business setting, Oracle Database can be used to manage customer data, sales data, financial data, and other types of data. For example, a bank may use Oracle Database to store customer account information, transaction data, and loan information. By using Oracle Database, the bank can ensure that the data is secure, accessible, and up-to-date, and use it to make informed decisions and improve its operations.
Microsoft Access: Microsoft Access is a desktop database management system that is widely used by small businesses and individuals to manage data. It provides tools for creating and managing databases, tables, forms, and reports, and can be integrated with other Microsoft applications such as Excel and SharePoint. In a business setting, Microsoft Access can be used to manage customer data, employee data, inventory data, and other types of data. For example, a small retail store may use Microsoft Access to track sales, inventory, and customer information. By using Microsoft Access, the store can organize its data, generate reports, and make informed decisions.
MongoDB: MongoDB is a document-oriented database management system that is designed for handling large volumes of unstructured data. It provides a flexible schema and can be used for storing and managing data such as social media posts, log files, and sensor data. In a business setting, MongoDB can be used to manage and analyze data from various sources, such as social media platforms, IoT devices, and online transactions. For example, a marketing agency may use MongoDB to analyze social media data and gain insights into customer behavior, preferences, and trends. By using MongoDB, the agency can tailor its marketing efforts to individual customers and improve customer engagement.
Hadoop: Hadoop is an open-source distributed computing platform that is used for storing and processing large amounts of data. It is commonly used in big data applications, such as data analytics and machine learning. Hadoop consists of two main components – the Hadoop Distributed File System (HDFS) and the MapReduce framework. In a business setting, Hadoop can be used to process and analyze large amounts of data from various sources, such as social media platforms, customer databases, and website analytics. For example, an e-commerce company may use Hadoop to analyze customer purchase history and website traffic data to identify market trends and optimize its product offerings. By using Hadoop, the company can process and analyze large amounts of data quickly and efficiently, and gain valuable insights into its operations and customers.
In conclusion, database management systems are essential tools for managing and storing data in a business setting. Oracle Database, Microsoft Access, MongoDB, and Hadoop are examples of DBMSs that can be used to manage and analyze data in various industries and settings. By using the appropriate DBMS, businesses can improve their operations, make informed decisions, and gain a competitive advantage. Effective use of DBMSs can lead to increased efficiency, productivity, and profitability.
Relational Databases
A relational database is a type of database that stores data in tables consisting of rows and columns, with each row representing a unique record and each column representing a field of data. The tables in a relational database are related to each other through a common field known as a primary key, which is used to establish relationships between tables. Relational databases are widely used in various industries, including banking, healthcare, retail, and education, among others.
Examples of Relational Databases
One example of a relational database is Oracle Database, which is used by many large organizations to store and manage large amounts of data. Oracle Database provides various tools and functionalities for database management, including backup and recovery, access control, and data replication. Another example of a relational database is Microsoft SQL Server, which is widely used by businesses of all sizes to manage their data. SQL Server provides various features such as Business Intelligence, which enables organizations to perform data analysis and make data-driven decisions.
Relational databases are also used in web applications to store and manage user data, including login credentials, user profiles, and preferences. For example, a social media platform like Facebook uses a relational database to store user data, including profile information, photos, and posts. The relationships between tables in the database enable Facebook to provide users with personalized content and recommendations based on their interests and interactions on the site.
Relational databases are also used in the healthcare industry to store patient data, including medical history, test results, and treatment plans. For example, a hospital’s electronic medical records system may use a relational database to store patient data, which enables healthcare providers to access and update patient information from different locations within the hospital. The relationships between tables in the database also enable healthcare providers to track patient progress over time and provide personalized treatment plans.
Another example of a relational database is a customer relationship management (CRM) system. CRM systems are used by businesses to manage their customer interactions and improve customer relationships. A CRM system may use a relational database to store customer data, including contact information, purchases, and interactions with the business. The relationships between tables in the database enable businesses to track customer interactions over time and identify trends and patterns in customer behavior.
In conclusion, a relational database is a type of database that stores data in tables consisting of rows and columns. Relational databases are widely used in various industries, including banking, healthcare, retail, and education, among others. Examples of relational databases include Oracle Database, Microsoft SQL Server social media platforms like Facebook, electronic medical records systems in hospitals, and customer relationship management systems used by businesses. Relational databases provide a structured and organized way to manage data, enabling businesses and organizations to make informed decisions and improve their operations. With the increasing importance of data in today’s world, relational databases will continue to play a critical role in managing and utilizing information effectively.
Linked Databases
One specific example of two simple relational databases that are linked by a key is a customer and sales database.
The customer database would contain information about each customer, such as their name, address, phone number, and email address. Each customer would have a unique primary key, such as a customer ID number. The sales database would contain information about each sales transaction, such as the date, product purchased, quantity, and price. Each sales transaction would also have a unique primary key, such as a sales ID number.
The two databases would be linked by the customer ID number, which would serve as a foreign key in the sales database. This would allow the sales database to reference the customer database and retrieve customer information for each sales transaction. For example, when a salesperson enters a new sales transaction into the sales database, they would select the customer from a drop-down list that is populated from the customer database. This would ensure that the customer information is consistent and up to date in both databases.
The linked databases would enable the business to perform various analyses and generate reports based on customer and sales information. For example, the business could generate a report that shows the total sales for each customer over a given period, the most popular products purchased by each customer, and the average revenue per customer. This information could be used to identify high-value customers, tailor marketing efforts to individual customers, and improve customer retention.
Furthermore, the linked databases could be used to automate various business processes, such as generating invoices and sending marketing emails. For example, when a sales transaction is entered into the sales database, an invoice could be automatically generated and sent to the customer via email. This would reduce the manual effort required by employees and improve the efficiency of the business.
In conclusion, linking two simple relational databases, such as a customer and sales database, can provide significant benefits to a business. The databases can be used to store and manage customer and sales information, generate reports and analyses, and automate various business processes. By using a primary key and foreign key to establish a relationship between the databases, the business can ensure that the information is consistent and up to date. Effective use of linked databases can lead to improved efficiency, customer satisfaction, and revenue growth.

Non-Relational Databases
A non-relational or flat-file database is a type of database that stores data in a plain text file, where each line represents a record and each value is separated by a delimiter character, such as a comma or tab. Flat-file databases are simple and easy to create but can become unwieldy as the data grows or becomes more complex.
Some examples of non-relational or flat-file databases include spreadsheets like Microsoft Excel or Google Sheets, where each row represents a record, and each column represents a field. Another example is a CSV (comma-separated values) file, which is a common format for exchanging data between different systems. Flat-file databases can be used for simple data storage, data manipulation, and data analysis, but they are limited in their ability to handle complex relationships between data or support advanced queries.
Unstructured, Structured, and Semi-Structured Data
Unstructured data does not have a predefined data model or format. It can include documents, images, audio files, videos, social media posts, and other types of data that are not organized in a structured way. Unstructured data is difficult to analyze using traditional data processing tools and requires specialized tools such as natural language processing and machine learning to extract insights.
Structured data is organized and formatted to a predefined schema or data model. It is usually stored in relational databases or spreadsheets and can be easily analyzed and queried using database management systems and query languages.
Semi-structured data has some structure but is not fully organized or formatted to a predefined schema. It can include data in formats such as XML, JSON, and CSV, which have some structure but may not conform to a strict schema. Semi-structured data can be processed using tools that can handle both structured and unstructured data, such as NoSQL databases and data lakes.
Database Query Languages
Database query languages are computer programming languages used to retrieve and manipulate data in a database. There are several types of query languages, including Structured Query Language (SQL), XML Query Language (XQuery), and Object Query Language (OQL).
Here are examples of queries in each language using a simple customer database example:
Various Query Language Examples
SQL Example:
SELECT * FROM customers WHERE last_name = ‘Smith’;
This SQL query retrieves all records from the customers table where the last name is ‘Smith’. The asterisk (*) is a wildcard character that selects all columns in the table. This query can be used to retrieve information about customers with the last name ‘Smith’, such as their address, phone number, and email address.
XQuery Example:
for $customer in /customers/customer
where $customer/last_name = ‘Smith’
return $customer
This XQuery retrieves all customer records from the customers XML document where the last name is ‘Smith’. The ‘for’ loop iterates over each customer element in the document, and the ‘where’ clause filters the results to only include customers with the last name ‘Smith’. The ‘return’ statement returns the selected customer elements.
OQL Example:
SELECT c FROM Customer c WHERE c.lastName = ‘Smith’
This OQL query retrieves all customer objects from the Customer database where the last name is ‘Smith’. The ‘SELECT’ clause specifies which object or objects to retrieve, and the ‘FROM’ clause specifies the database or table to retrieve them from. The ‘WHERE’ clause filters the results to only include customers with the last name ‘Smith’.
In conclusion, database query languages are essential tools for retrieving and manipulating data in a database. SQL, XQuery, and OQL are examples of query languages that can be used to retrieve data from a customer database. By using the appropriate query language, businesses can retrieve information about their customers and use it to make informed decisions and improve their operations.
Big Data
Big data refers to the large volume of complex and diverse data generated by digital platforms, devices, and applications. It includes structured, unstructured, and semi-structured data that is too large to be processed by traditional data processing tools. Big data is important to businesses because it provides valuable insights into customer behavior, market trends, and operational efficiency. By analyzing and understanding big data, businesses can make data-driven decisions, improve their products and services, and gain a competitive advantage.
Big data is used by businesses to gain a competitive advantage in several ways. One way is through customer analysis, which involves analyzing customer data to gain insights into their preferences, behavior, and needs. This can help businesses personalize their products and services, improve customer satisfaction, and increase customer loyalty. Another way is through operational analysis, which involves analyzing internal data to identify areas of inefficiency and improve processes. This can help businesses reduce costs, increase productivity, and optimize their operations. Additionally, big data can be used for market analysis, which involves analyzing data from external sources to identify market trends, opportunities, and threats. This can help businesses identify new markets, develop new products and services, and stay ahead of the competition.
In conclusion, big data is important to businesses because it provides valuable insights into customer behavior, market trends, and operational efficiency. By using big data, businesses can make data-driven decisions, improve their products and services, and gain a competitive advantage. By analyzing and understanding big data, businesses can better understand their customers, optimize their operations, and identify new market opportunities.
Data Modeling and Analysis
Business data modeling and analysis involves the process of creating a conceptual representation of an organization’s data, identifying and integrating relationships between different data elements, and analyzing the resulting data for better decision-making. It is an important aspect of modern business management and helps organizations to effectively manage their data assets.
Data mining is a process of extracting insights and knowledge from large datasets, typically using statistical and machine learning techniques. It is useful for identifying patterns, relationships, and trends in data that might not be apparent using traditional analytical methods. Data mining can be used to improve decision making, drive new product development, and optimize operations.
Data visualization is the graphical representation of data, which helps to identify patterns and relationships in a more intuitive way. It is often used to communicate complex data concepts in a simple and easy-to-understand manner. Data visualization helps managers and executives to get a clear picture of their business operations and make informed decisions based on that understanding.
Descriptive analytics involves the use of statistical and mathematical techniques to describe and summarize data. It is a crucial aspect of business data modeling and analysis, as it helps to identify trends, patterns, and relationships in data that can assist in making better decisions. Descriptive analytics involves techniques like data profiling, regression analysis, and cluster analysis.
In summary, business data modeling and analysis involves leveraging data mining, data visualization, and descriptive analytics techniques to manage and derive insights from an organization’s data assets. By doing so, businesses can make better decisions, improve performance, and gain a competitive advantage.
Example: Amazon and Data Mining
One example of a company that used data mining for business success is Amazon. Amazon is the world’s biggest online retailer and has been using data mining to better understand their customers’ behavior and preferences.
In the late 1990s, Amazon started collecting data for every product purchased on their website. This data included items such as users’ purchase history, search queries, time spent on the website, products viewed and clicked, and many other metrics. With the help of machine learning algorithms, Amazon was able to use this data to create personalized recommendations for each customer based on their preferences.
As a result of this data analysis, Amazon was able to achieve numerous benefits. Firstly, they were able to provide personalized recommendations to users which increased the chances of repeat business. These recommendations were highly accurate, and it was common to see an increase of 30% or more from shoppers returning to their website to buy products that were recommended to them.
Secondly, Amazon was able to optimize the user experience for their customers by providing a highly personalized and targeted experience. This created a customer-focused approach that stood out against their competitors, helping to increase customer loyalty and retention.
Finally, data mining allowed Amazon to identify trends in their vast quantities of data that were not visible before. These insights provided a significant competitive advantage for Amazon in the online retail market, allowing the company to stay ahead of the curve and adapt quickly to changing consumer behavior.
In conclusion, Amazon’s use of data mining has been instrumental in their success, with personalized recommendations and a highly targeted customer experience leading to increased customer loyalty and revenue. The identification of trends in their vast quantities of data has allowed Amazon to stay ahead of the competition in the online retail market, and they continue to use data mining and analytics to improve their business operations.
Summary
This chapter focuses on Data Management and Analytics, which are essential components of any successful business. The chapter covers the basics of data, data storage and retrieval, database management systems, and data modeling and analysis.
Data is the foundation of any business, and understanding it is crucial for decision making. Data are essentially facts, figures, and statistics that are collected and stored for future use. This could be anything from sales figures to customer profiles, and it is important to categorize and organize data so that it can be used efficiently. Data can be classified into two categories: structured data and unstructured data. Structured data is organized, labeled, and stored in a format that can be easily retrieved, whereas unstructured data refers to data that is not organized and includes text, images, and videos.
Data storage and retrieval are necessary to maintain and access data easily. The primary means of storing data are files and databases. File storage is simple and low cost, but it lacks the capacity for efficient retrieval of specific data. Database storage, on the other hand, is organized and designed for easy retrieval of specific data. Database management systems (DBMS) are software applications used to manage the storage and retrieval of data. DBMS can be classified into Relational DBMS and Non-Relational DBMS. Relational DBMS organizes data into tables that can be linked together to create complex structures for storing information.
Data analysis is an essential tool used in decision making. Data analysis summarizes data to describe what happened in the past and identify the root cause of this issue. Once the root cause has been identified, steps can be taken to address the problem. By identifying the underlying causes of issues and taking concrete steps to address them, organizations can improve performance, increase effectiveness, and drive long-term success.
Discussion Questions:
- What is the difference between structured and unstructured data?
- How can data be stored and retrieved efficiently?
- What are the main components of a database management system?
- When should I use a relational database versus a flat file database?
- How do you approach data cleaning and preparation for analysis?
- What is the difference between supervised and unsupervised machine learning?
- How do you choose the best algorithm for a given analysis?
